
Hace unos días leía en el blog de eferro sobre la idea de tests de mutación y me hizo pensar en otros tipos de tests, concretamente cuando tenemos que imitar o emular la respuesta de una de nuestras dependencias.
Crear estos datos es un proceso que, habitualmente, consume tiempo y muchas veces no merece la pena especialmente si nuestras dependencias van cambiando. En el artículo anterior usábamos LLMs para entender el código de nuestras aplicaciones, y hoy vamos a usarlos para entender el comportamiento de las mismas, o más bien simular el comportamiento con nuestras dependencias, incluyendo errores, latencia o datos incompletos.
Este es un artículo diferente, en el que cada sección muestra un prompt nuevo sobre el código que fuimos construyendo en la sección anterior. Acompáñame en esta aventura de mocking agresivo.
Banco de pruebas
Para este ejemplo usamos Visual Studio Code con Cline y el modelo Haiku 4.5 de Anthropic y creamos una aplicación muy sencilla usando ExpressJS y la conectamos a la API de Strava, la aplicación de deporte, en la que tengo algunos datos y ya usé en el pasado para el artículo de Cloud Running.
/deep-planning Create an extremely basic express app that has a simple HTML output with a couple variables.De ahí fuimos a la API de Strava, a buscar la lista de actividades y le dijimos a nuestra app que queríamos un agregado muy sencillo de las actividades:
/deep-planning We want the Index to be an aggregated list of an athlete's activities.
Check this API https://developers.strava.com/docs/reference/#api-Activities-getLoggedInAthleteActivities
And this JavaScript example
var StravaApiV3 = require('strava_api_v3');
var defaultClient = StravaApiV3.ApiClient.instance;
// Configure OAuth2 access token for authorization: strava_oauth
var strava_oauth = defaultClient.authentications['strava_oauth'];
strava_oauth.accessToken = "YOUR ACCESS TOKEN"
var api = new StravaApiV3.ActivitiesApi()
var opts = {
'before': 56, // {Integer} An epoch timestamp to use for filtering activities that have taken place before a certain time.
'after': 56, // {Integer} An epoch timestamp to use for filtering activities that have taken place after a certain time.
'page': 56, // {Integer} Page number. Defaults to 1.
'perPage': 56 // {Integer} Number of items per page. Defaults to 30.
};
var callback = function(error, data, response) {
if (error) {
console.error(error);
} else {
console.log('API called successfully. Returned data: ' + data);
}
};
api.getLoggedInAthleteActivities(opts, callback);
And add the aggregation logic to the / pathEl resultado es este:
Jugando con los tiempos
Mi primer objetivo fue agregar tiempos de espera y errores, para ver cómo reaccionaba la interfaz.
I want to create a mock the strava API request to take 5 seconds to load and then timeout, the response will be a Fault object as per the Strava API: https://developers.strava.com/docs/reference/#api-models-Fault
To trigger the mock, i want to pass a parameter called mock=slow_timeoutLa solución que daba era demasiado ad-hoc, algo bastante común cuando usamos LLMs, asi que tuvimos que recurrir a ampliar la pregunta.
I'm going to create additional mocks, so prepare the code to process different mock types, an enum maybe?Las respuestas me permitieron generar espacio para que el LLM razonara de manera independiente, y en el caso de Cline, presentó diferentes opciones para crear mocks adicionales, pero el objetivo de este ejercicio era ir un poco más despacio.
Una vez creado el mock «lento», el siguiente paso fue adaptar la UI para que respondiera a este tipo de operaciones, convirtiendo la carga de síncrona en asíncrona:
Now that we have a slow loading page, our app is not responsive, so let's create an /api path in our express app, a loading spinner in our main app, and an error message that is specific to timeout.
El resultado es este:

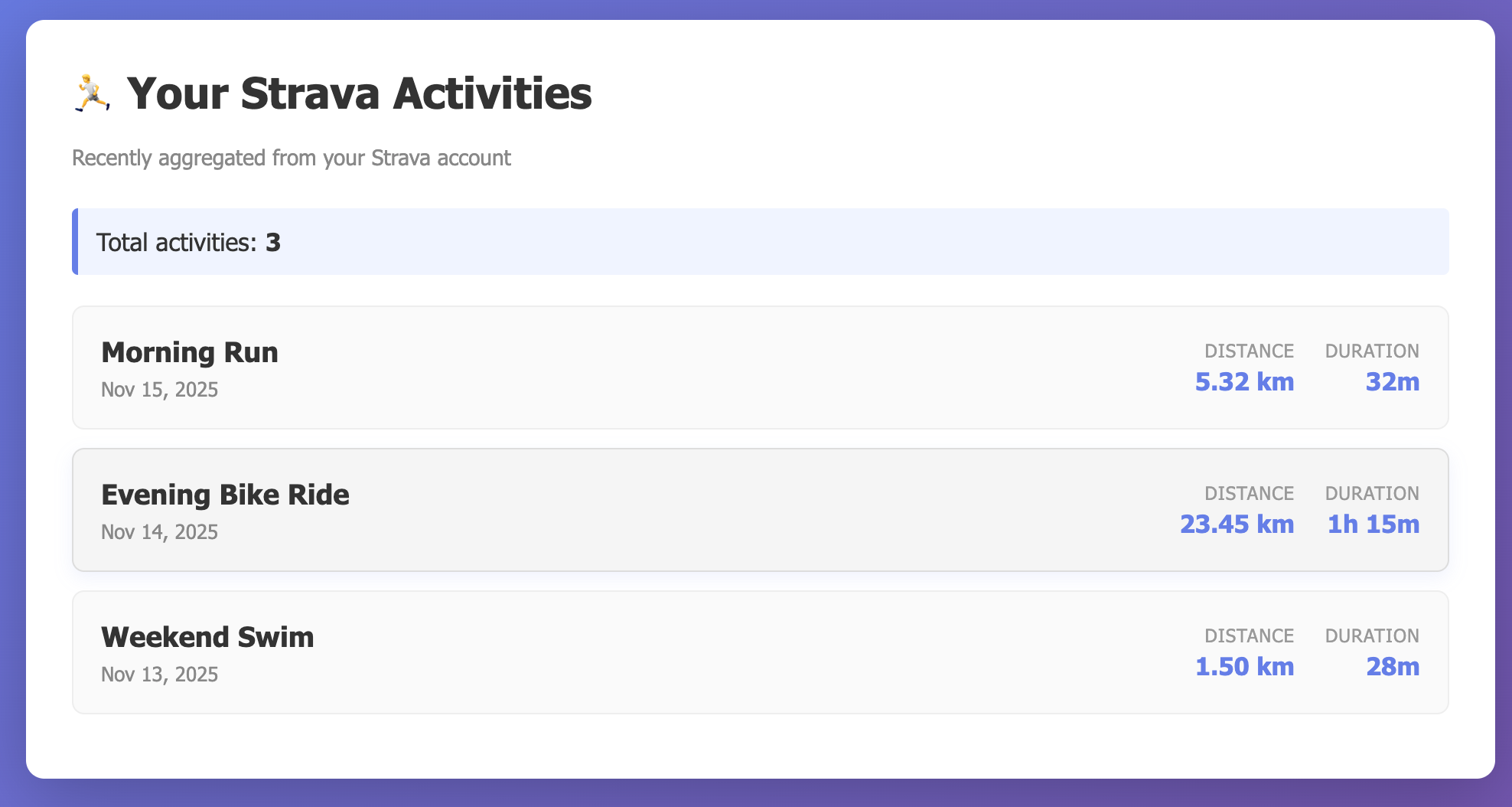
Una vez que tuvimos la respuesta lenta, el siguiente paso fue generar la respuesta «rápida»:
Now I need to have the happy path, let's go for a "fast_accurate" load that responds with the right data.Aquí tuvimos el primer problema, y era que el modelo especulaba sobre la estructura de los datos, así que tuve que especificar un ejemplo de respuesta (el termino que solemos tener asociado a ese tipo de prompt es One-Shot https://cline.bot/blog/prompt-fundamentals?ref=cline.ghost.io) :
Check the expected API responses and return something that complies with that:
[JSON]El resultado final es rápido y correcto, como queríamos:
Desacoplando
Otro de los problemas de los LLMs es que no son capaces de entender la intención del código, y en el caso de este ejemplo, habían mezclado el código de mock con el código principal, así que el siguiente paso fue eliminar acoplamientos:
We have an app that has mock data embedded with business logic, we need to extract all mock handling into a different file, and reduce the coupling between the mocking and the business logic, so we can toggle it off and on easily. Give me options.El modelo dio 5 opciones diferentes, y me recomendó un patrón estrategia, es decir, tener una clase que proporciona la respuesta real de la API y otra que proporciona los mocks. Este patrón lo he usado otras veces y es bastante limpio así que me pareció una buena idea. Para asegurarme que la implementación era limpia, agregué un requisito para usar metadatos:
Strategy pattern it is, but with a twist, let's load the mock data from json files and let's make it metadata_driven, so adding additional mocks doesn't require code changes.Más casos de uso
Una vez tuvimos la estructura preparada, el siguiente paso fue delegar en el LLM para que nos proporcionara diferentes casos de uso.
We have an app with a mock system, let's analyze the response, the mocks and build a list of mocks that help us with additional test cases. Give me optionsLa respuesta no se hizo esperar, 7 mocks cubriendo los siguientes escenarios:
- Respuesta vacía
- Errores de autenticación (401, 500, 429)
- Latencia pero correcto
- Datos incompletos
- Dataset grande
Durante la ejecución, el propio modelo fue detectando cuando la aplicación no se comportaba correctamente de acuerdo con los mocks y hacía los cambios correspondientes del código «de producción». Para ello fue imprescindible el modo «Browser» que tiene Cline, que permite interactuar con un navegador.
Mock discovery
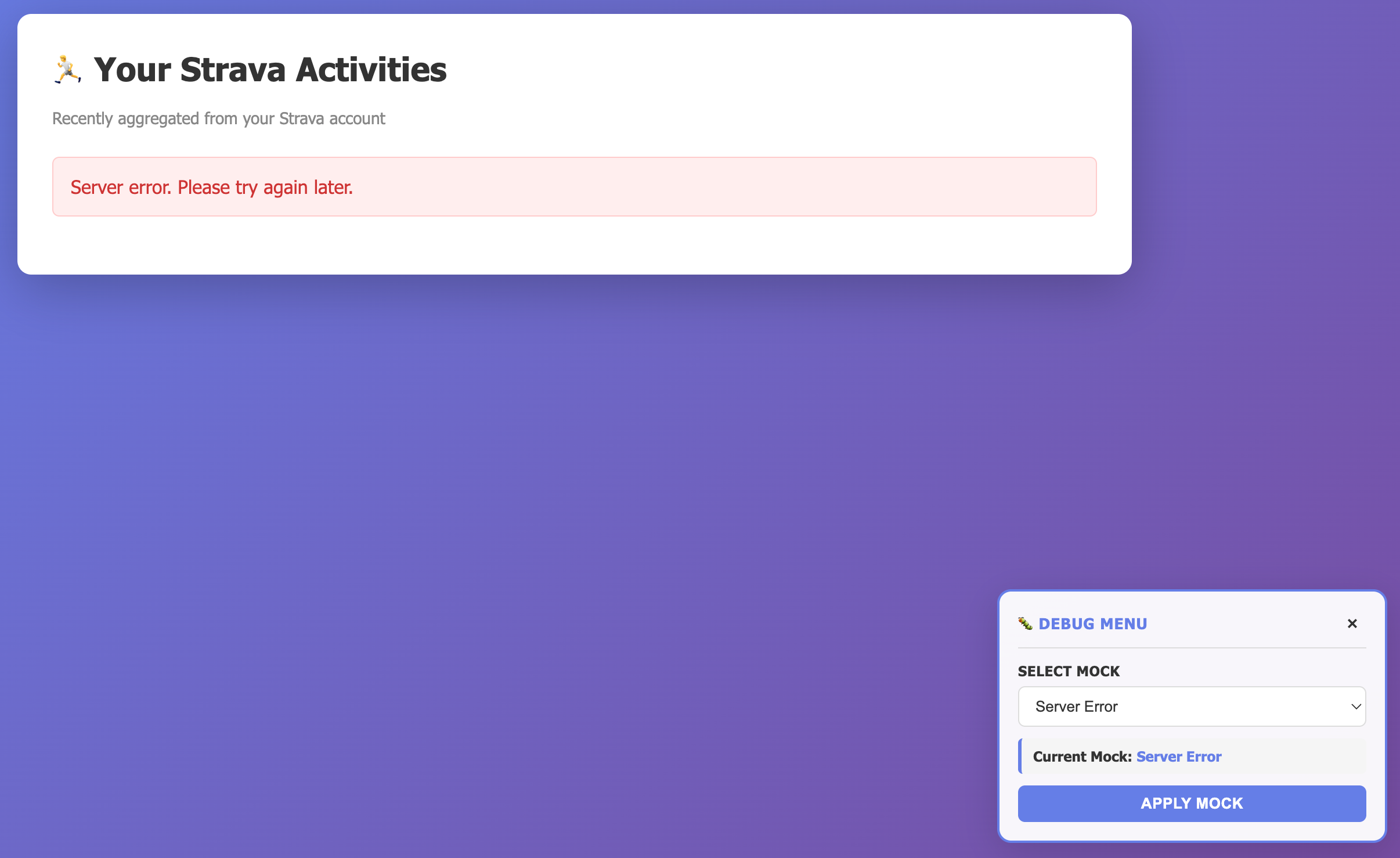
Otra de las características en las que estaba interesado, era agregar la capacidad para seleccionar los mocks desde la propia interfaz, así que el siguiente paso fue hacer un cambio a más alto nivel para generar una consola de depuración:
We have an app that has a mocking system, but we have a discoverabilty problem, from the UI there's no way to choose a prompt. Let's inject a debug menu (floating, with minimum impact in the production code) that allows us to choose a mock and refreshes the page accordingly. Triggering the menu would requore the parameter debug=trueEl sistema sugirió crear un nuevo endpoint para cargar la información de json, pero quise mantenerlo simplificado:
Let's not create a json response for the mocks, I'll choose compromising page load for simpler architecture.El resultado fue impresionante, aunque un poco caótico, ya que creó el código de gestión de mock en la vista, vamos a corregir esto:
Minor change, instead of hardcoding the mocks list, let's read it from the metadata.json file, and extract the debug menu into a debug.js fileTras ese cambio, el resultado fue el que vemos a continuación;
Traffic replay
Hasta ahora habíamos probado con datos sintéticos, pero el siguiente paso fue poder tener datos reales y usarlos en escenarios en los que no tuviéramos conexión (trabajo en local o acceso a un conjunto de datos diferentes).
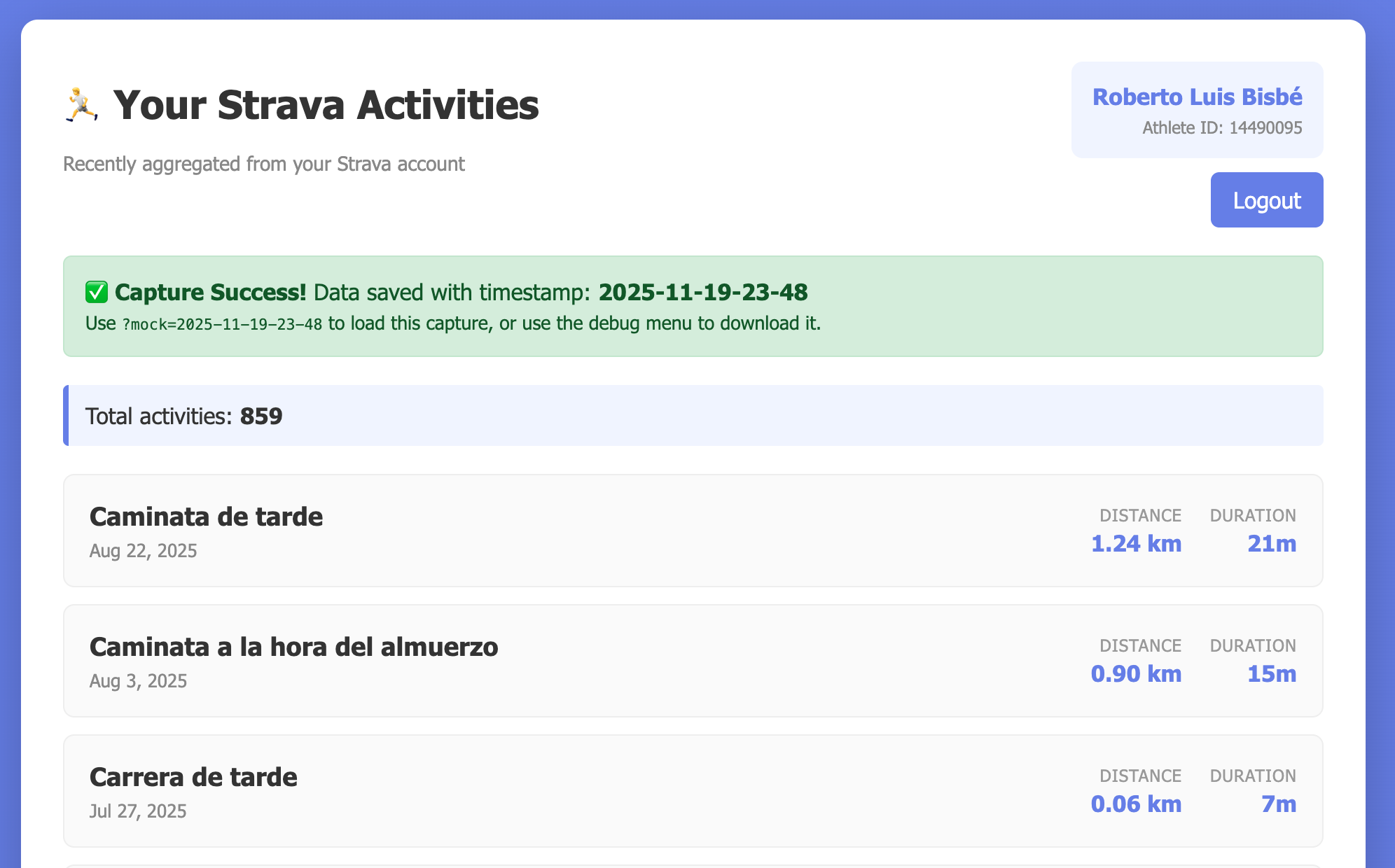
Para este ejemplo, implementamos un sistema de Traffic replay que permitía capturar las respuestas de Strava y convertirlas en mocks para nuestro sistema.
We have an app that has mocked data and that also has real data, I need a way to capture the data from the call to the real API, so that I can use that data "offline". I'm thinking about a parameter called capture that basically creates a mock out of the captured data with a timestamp (2025-11-19-23-29) and leaves it in the browser storage, that way I can then use mock=2025-11-19....El resultado fue espectacular, tras un par de aclaraciones tuvimos un mecanismo por el que podíamos capturar la respuesta de Strava, generar un timestamp para localizar la captura o incluso guardarla para agregarla a nuestro sistema.
Resumen y costes
El proyecto completo fueron una hora y media de prompting y $2.28 en créditos de Cline, que incluyó crear la aplicación de ejemplo desde cero, aproximadamente 8,700,000 tokens de entrada y 122,000 tokens de salida. Cada sesión empezaba «desde cero» con lo cual, más allá del código, los agentes no tenían contexto adicional.
Con este pequeño ejercicio vimos que podíamos agregar mocking a sistemas existentes, lo que nos permitió acelerar nuestro desarrollo y probar el comportamiento de nuestras aplicaciones en escenarios que son más complicados de probar cuando tenemos dependencias.

Deja un comentario