
Esta semana he estado leyendo sobre Backend For Frontend o BFF, un patrón de arquitectura de microservicios dio a conocer al mundo uno de los ingenieros de SoundCloud en el año 2015, aunque sigue aplicándose a día de hoy.
En este artículo veremos el problema que tenemos en un entorno de microservicios y cómo el patrón BFF es una de las soluciones posibles.
El problema
Una aplicación web presenta diferentes niveles de complejidad en función de la necesidad. El ejemplo más básico es el de un único sistema que genera el contenido de lado del servidor, donde tanto el frontend como el backend forman parte del mismo, lo que se considera un monolito (por ejemplo, este blog).
Este sistema se puede hacer más complicado si convertimos este monolito en un conjunto de APIs REST unido a un código más complicado del lado del cliente (una Single Page Application o SPA) (o un estéreo-liso). Hasta este momento tenemos una única conexión entre cliente y servidor.
La complejidad puede aumentar mucho más por dos lugares diferentes. Por una parte, podemos necesitar soportar otros canales, como una aplicación móvil, una skill de Alexa, o una API para terceros. Por otra, el backend se puede dividir en diferentes servicios, cada uno con una API específica, a la que nos tendremos que adaptar.
Llegados a este punto, nos encontramos en una posición en el que los clientes (la aplicación móvil, la aplicación principal, la skill de alexa y un desarrollador independiente) dependen de una API común o de una serie de APIs independientes, con lo cual se genera un acoplamiento fuerte entre dos o más sistemas.
El resultado es que todos los clientes acceden a APIs que dan mucha más información de la que ellos necesitan, y no tienen una manera específica de controlar qué información utilizar y cómo leerla. Además, esto limita la capacidad de los desarrolladores de la API, ya que de repente cualquier cambio tiene que ser consensuado con todos los clientes, aumentando la probabilidad de generar regresiones.
La filosofía
La filosofía propuesta por BFF intenta simplificar la relación entre un cliente y su servidor, generando un punto de entrada para cada cliente. Esto significa que un cliente accede a una API exclusiva que soporta casos de uso específicos de cada cliente y que el cliente tiene total libertad para adecuar su API a sus propias necesidades.
En un patrón de microservicios, esto significa generar un servicio intermedio que de soporte única y exclusivamente a este tipo de cliente. Este servicio, desde el punto de vista de pertenencia, le pertenece al equipo del cliente. Volviendo a nuestro ejemplo, el equipo de la Skill de Alexa tendrá una API diferente al equipo de la app móvil, que el de la aplicación de escritorio.
La ventaja principal, que he comentado anteriormente, es que se simplifica el acoplamiento entre una aplicación y sus servicios de backend. Además, es más fácil que un servicio de backend evolucione, ya que las adaptaciones no necesitarán desplegar nuevos cambios en cliente, sino solamente en los adaptadores.
El ejemplo
Supongamos que queremos diseñar la siguiente iteración de Pokemon Go, tenemos una aplicación móvil en la que capturaremos los Pokemon, una web donde podemos ver detalles de nuestras capturas y una Skill de Alexa en la cual podemos saber en qué posición estamos del ranking.
En un desarrollo tradicional con un único endpoint, tendríamos una API REST en el cual todos los clientes efectuarán las llamadas necesarias, todos los clientes utilizarán el mismo protocolo y tipo de datos.
Este sistema convierte nuestra API rest en un punto de fallo para tres sistemas diferentes, con el añadido de que, salvo el sistema web, un fallo que rompa los clientes de iOS y los de la Skill de Alexa pueden tardar en corregirse, ya que depende de las reglas de cada marketplace.
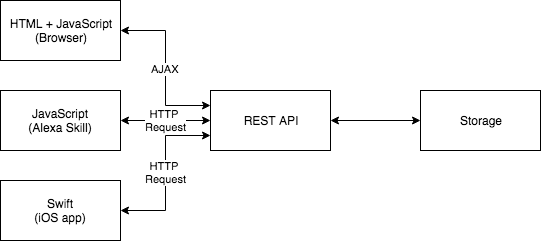
Por otro lado, ¿que pasaría si cada cliente tuviera un servicio asociado? Esto provocaría un aumento considerable en la libertad de los diferentes equipos en desarrollar soluciones en el servidor para sus problemas específicos.
- El equipo que gestiona la web podría decidir en utilizar GraphQL para generar solamente una petición, y utilizar código isomórfico para tener JavaScript en cliente y servidor.
- El equipo que gestiona la Skill de Alexa podría utilizar una opción servirles en Lambda utilizando Python.
- El equipo que utiliza la aplicación iOS, con el objetivo de ahorrar ancho de banda a los clientes, puede decidir montar un servicio a bajo nivel con un socket TCP.
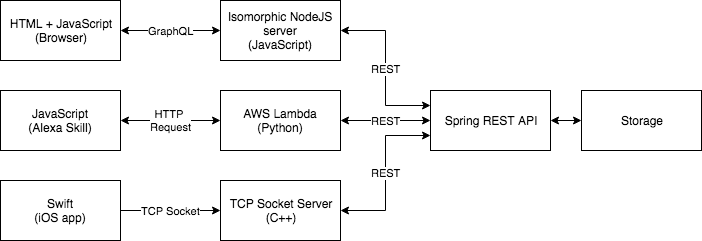
Este cambio no afecta a la lógica de negocio, ya que estos servidores seguirán llamando a nuestro servicio común, que a su vez puede evolucionar de manera separada dividiéndolo en otros tantos servicios.
Esto permite además una evolución mucho más rápida de los sistemas, ya que en caso de un cambio importante, solamente será necesario actualizar los servicios intermedios, y las aplicaciones cliente pueden continuar funcionando.
Los inconvenientes
El principal problema de utilizar una API para cada tipo de cliente es la complejidad, de repente tener un servicio y tres aplicaciones cliente se convierte en tener tres servicios, tres aplicaciones cliente y un cuarto servicio por encima de todas ellas. Esta complejidad no está exenta de coste, lo cual puede repercutir en más hardware, más configuración y encarece el desarrollo.
Otro problema de esta aproximación es que requiere que los equipos de cliente tengan capacidad para generar su propio servicio de backend, lo que implica tener conocimientos de backend en un equipo frontend o un equipo mobile, lo cual no siempre es el caso.
El dilema de dogfooding
Dogfooding (o “eat your own dog food”) es el término que en ocasiones empleamos para utilizar las mismas herramientas y APIs a las que pueden acceder nuestros clientes externos, idealmente con el objetivo de no crear ciudadanos de primera y de segunda.
Sin embargo el peligro que tiene una API pública es el riesgo de romper a clientes externos con cambios que tengan sentido de manera interna pero no de manera externa, así que podríamos considerar la API pública como una API más, con una evolución diferente.
La decisión, to bff or not to bff?
La respuesta es, como siempre, depende. Si tenemos un sistema en el cual un tipo de cliente solamente va a utilizar un subconjunto de la API principal, puede ser buena idea crear un acceso solamente para este tipo de clientes. Ejemplo: Una skill de Alexa para agregar elementos a una lista de tareas, y un portal web para administrarlas.
Si, por el contrario, todos nuestros clientes van a utilizar los mismos métodos de nuestra API, y todos los clientes van a ser exactamente iguales en cuanto a funcionalidad, es posible que no necesitemos más que una API para gobernarlas a todas.
Echando la vista atrás recuerdo un ejemplo muy claro en el que tener un servicio genérico con el objetivo de soportar varios tipos de cliente condicionó muchísimo el diseño del primer y único cliente que se terminó desarrollando, agregando un montón de lógica al cliente de manera innecesaria para adaptar los datos que venían del servicio. Esto se podría haber evitado considerando que el servicio iba a tener un único cliente.
Resumen
BFF es un patrón de diseño de microservicios que nos permite considerar que el acceso a nuestro servicio se realiza desde clientes específicos con necesidades específicas, permite evolucionar las diferentes capas de la aplicación de manera paralela y elimina acoplamiento entre clientes diferentes con casos de uso específicos, siempre y cuando podamos asumir los costes de tener diferentes puntos de entrada a nuestra aplicación mantenidos por diferentes equipos.
Si quieres leer más del tema te recomiendo que eches un vistazo a los siguientes artículos:

Deja un comentario